
Designing a successful data analytics platform for a rapidly changing world
Key design principles we learned while building Streamhub’s video data analytics platform
We are in the age of data where you can change the ending of a film if it doesn’t match your taste! Black Mirror‘s ‘Bandersnatch’ is Netflix’s first major interactive film where its script has millions of permutations.
“It’s an ambitious film that saw Netflix making several innovations in its platform, such as reworking its cache memory to store multiple scenes or creating the ‘Branch Manager’ to help Charlie Brooker write the script.”
Another significant milestone for data-driven content creation, following on from the story behind the blockbuster Netflix remake of ‘House of Cards’.
From ‘House of Cards’ to ‘Bandersnatch’, what is that key ingredient of Netflix’s success formula? Innovation!
Netflix has always pushed the boundaries of disruptive innovation, revolutionising how we consume content everyday!
Simply put, innovation is the key to be ahead of the game for any company relying on data – innovating before your competitors, answering complex questions with confidence and rapidly adopting the latest powerful and sophisticated analytics tools.
If you happen to be a start-up, cost and resource limitations make it that more challenging whilst having the upside of flexibility, rapid decision-making and higher risk-taking.

What we have learned
At Streamhub, we have always been good at adopting the latest technologies. From RDBMS to HBase, Cassandra to Elasticsearch to Apache Spark to Redshift to Clickhouse to Apache Druid to Snowflake, we have seen it all! We have been spending a lot of time in switching between technologies to respond to changing business demands, adapting the platform for different customers, heavy integrations and so on. And as we all know, change is part of the game. For a long time however, we had little time to sink our thoughts into fundamental innovation to consider how to build the foundation of our technology to embrace change more easily.
There is also another side to it. The ‘modern’ wave of data analytics based on ‘distributed computing’ has rapidly evolved from Hadoop to Google’s MapReduce followed by Apache Spark and ‘analytics in the cloud’ making it possible to analyse a large set of data in almost a couple of clicks without leaving the desk! This has made the space even more competitive and now more than ever it has become vital for data businesses to focus on rapid development and innovation.
This article talks about how you can design your big data system iteratively so you can continually respond to opportunities without putting too much cost from the get go and still make it flexible to adopt future business needs.
We will take you through five principles which are intended to introduce modularisation in your pipeline through tiering, the range of technologies that you can exploit, dimensions based on which we can separate these technologies, yet keep the core analytics narrow and defined, and keep yourself fast paced while keeping the costs in check.
We highly recommend giving this a thought, no matter which stage your company is in. This has helped us not only set futuristic direction for the technology but also helped the product in understanding the reach of data, identifying low hanging features and getting a hint of time-consuming future features so we could plan; keeping development, product and sales strategy in sync. This article is meant for data technologists, architects and early data technology adopters or data-related business people.
1. As veterans of data say “design in tiers”, but also do think between the tiers.
Data tiering is about moving data across a pool of storage to optimise cost and performance, which traditionally is between ‘hot’ or ‘warm’ servers or ‘archived’ storage. With more technologies involved in modern systems, this extends to cross technologies and cross cloud platforms. Data usually progresses through four broad tiers: In-transit, raw, cleansed & optimized, specialized-persistence. These tiers might break up further based on your business case. Our our reference, let’s take this example:

Tiering helps you make your analytics system modular, which provides flexibility so that your organization can meet its ever-changing business requirements. Tiers could be based on:
- Capacity/Archive: To ensure that you are using the storage capacity optimally, you need to design how your data moves, based on time or access pattern, such that your storage best fits the performance requirements while keeping the cost in check. For example, move the data to AWS Glacier when it is older than 6 months or use S3 intelligent tiering to move infrequently accessed data to Glacier.
- Standardization: If you are collecting data from several sources or for different customers, you may want to standardize them into a common format, so you don’t have to deal with this in downstream layers.
- Personally identifiable information (PII) segregation: You may want to remove personally identifiable information (PII) while data is in-transit, before it lands your storage.
- Storage tiering for performance within a datastore: Tier your storage as ‘hot’ and ‘warm’ zones which can be based on type of disks or instances. For example, with Elasticsearch, you can set an arbitrary attribute that can tag node server as hot or warm and set routing in a way that your recent data is routed to hot nodes while the rest is stored in warm nodes.
- Persist to optimal datastore for specialised use-cases. For example, persist your data in a column-oriented database or an OLAP datastore for deep-dive analytics or pre-aggregate and scan for quick access or run through some ML model and store in some tree database for shortest path use cases.
- Storage caching to optimise performance: Technologies like Alluxio or Apache Ignite provide distributed in-memory cache which can help you run your queries, let’s say Spark queries over Alluxio, blazing fast by sharing the data cross jobs.
- Optimal input format for analytics platform: For example, you may want to store your data in columnar format like ORC + Zlib to optimise cost for your data lake solution, while in Databricks-Delta format for other ML use cases so you can exploit it’s time travel feature.
- Across cloud platforms: You can also move your data across the cloud to use specific services of a cloud platform or to manage cost. However, it is always more complex and expensive to move data across cloud unless there is strong motivation to do so.
Since your data is moving between the tiers, you might need to access the data for validation or exploration for your business intelligence use cases. So you would need some analytic tool over these tiers, if possible on-demand, serverless and SQL-like so it is cost effective and easy to use. If you are on the cloud this tool can be AWS Athena or Google Big query or Azure data lake. I will elaborate on this later in the article.
So a simple pipeline may look something like this:
Automated workflows and processes are necessary in order to reap the benefits of tiering. You would need to command some orchestration tools which can be a combination of services provided by your cloud platform, like AWS step functions, CloudWatch/SNS; and/or open-source options like Airflow, Luigi, Piper, etc. Automating your workflow definitely makes your life easier, at the same time, parts which are difficult to automate you can always start running manually first, optimize them and then consider automating. During the initial phase, your workflow might change many times.
Also, think about the data archiving, purging and data recovery process. If your pipeline breaks at any time, how would your support team be informed? How would you recover the data? Would it be manual or automatically triggered?
2. “No one datastore would fit for all your use-cases” – get away from that monolithic thinking!
If you have been in an analytical business for a while, you would know that the scope, scale and depth of data requirements change very quickly. Teams may decide to move from one technology to another to cover all, and you will spend most of your time in ‘migrations’. This could be a sign of monolithic design.
Let’s try a dumb but simple pictorial demonstration. As you go from left to right through these tiers (let’s take the example of the pipeline above), the analytical properties each tier offers are very different. It’s obvious, you would like your ideal solution to have the following properties: cost-efficient at storage / compute / operations, data queryable as soon as it lands, highly concurrent and performant even with inconsistent traffic, elastic volume – being able to query the good extent of data from the latest to archived data and handle all your specialised use-cases.
In the picture below, the intensity of properties is increasing as you go outwards, so the ‘dashed’ one is our ideal solution. The same properties for analytic solution over T0 (green), T1-2 (blue) and T3 (crimson) are marked relative to each other. You may have many ‘specialised’ use-cases – I am skipping the further break down of T3 but if you do, it can add more properties to your ideal analytical system.
As you must have noticed already, our ideal solution is a combination of all these different solutions! Instead of pushing all that pressure to one database and choking it, begin by designing your “ideal” solution as a combination of different analytical services and datastores.
- Identify the tiers you are exposing for analytics.
- Identify the broad use-cases your exposed layers must cover.
- Design for your specialized use-cases. Pick the best fit analytical platforms or datastores.
- Think hard about data refresh or update schedules, versioning and retention/clean-up before you pick technology.
- Once you have your best solution on paper, pick a subset that ticks your important features within your cost and resources your company can afford at the moment. As you grow, you might want to get closer to your ideal solution.
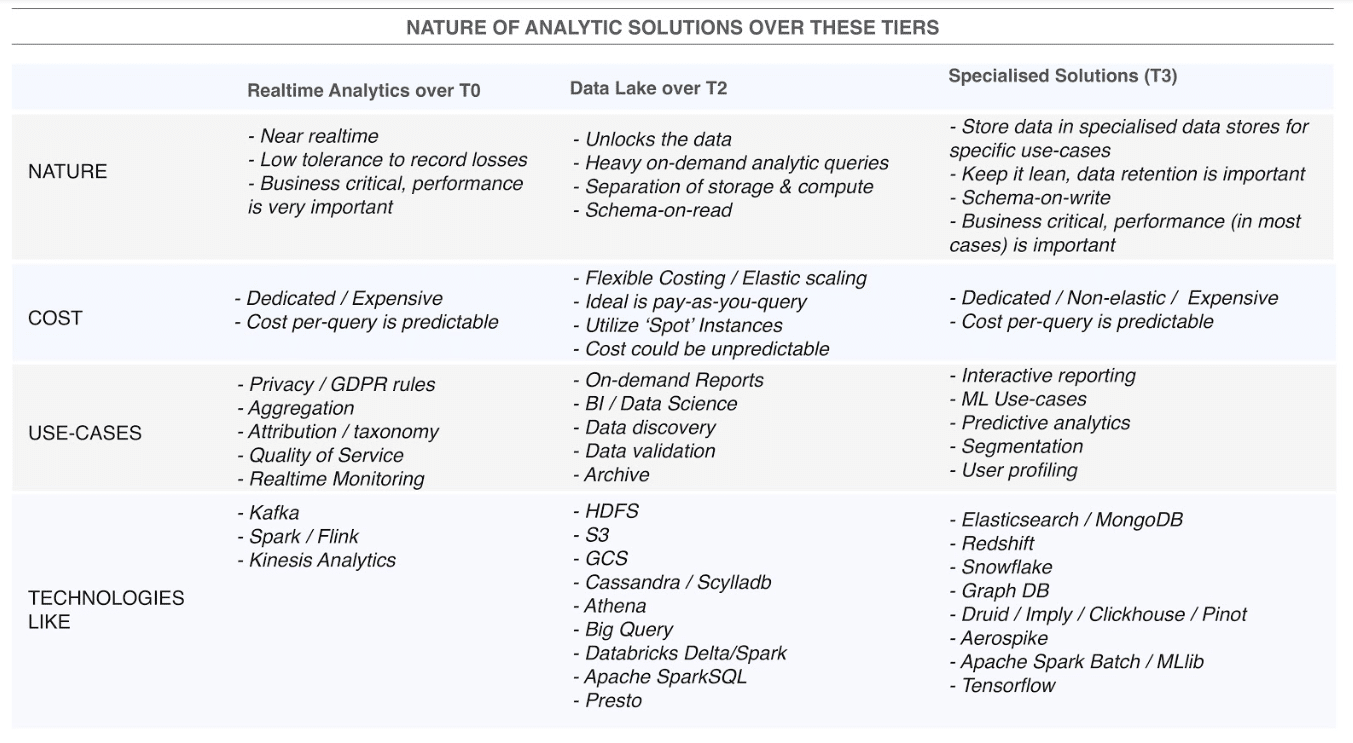
3. Master a distributed processing framework for large scale data processing but do not underestimate the power of SQL-like severless engines!
Hadoop MapReduce emerged as the first and fastest way to extract business value from massively large datasets through distributed processing over commodity hardware, followed by tools such as Hive, HBase, Pig, etc. Fast forward a couple of years, Apache Spark emerged claiming to be much faster than Hadoop MR, along with streaming and ML capabilities. An excerpt from Wikipedia which compares the two: “MapReduce programs read input data from disk, map a function across the data, reduce the results of the map, and store reduction results on disk. Spark’s RDDs function as a working set for distributed programs that offers a (deliberately) restricted form of distributed shared memory.“
Since Spark can also use HDFS for data storage and YARN for cluster management, it can run on AWS’s Elastic MapReduce clusters and GCP’s Dataproc clusters. In the data analytics world, it almost became fashionable to use Apache Spark!
No doubt Spark serves a broader range of analytic tools through Streaming, MLlib and GraphX tools. But if we are considering only simple batch use-cases querying on terabytes scale, the serverless SQL-like services provided by AWS and Google are pretty powerful and come handy!
Google describes Bigquery as cloud data warehouse that supports super-fast SQL queries using the processing power of Google’s infrastructure. Bigquery is powered by other Google technologies like Dremel (execution engine), Borg (compute), Colossus (distributed storage) and Jupiter (network) packaged such that it is convenient for running ad hoc queries across very large databases. While AWS describes Athena as an interactive query service for conveniently analyzing data in S3 at low cost and without needing to set up a complex infrastructure. It is a managed PrestoDB engine. You can also run Presto on EMR but you have to manage your cluster while Athena is fully managed. For both the technologies you pay for what you use. These are meant for only batch loads, they would not be the right choice for client facing applications directly due to limited concurrency which cannot be scaled after certain limit per account.
Also, there are cloud-based Datawarehouse solutions like Snowflake, Redshift, recently emerging Firebolt, that are pretty easy to work with while it gives you the power of a full-fledged data warehouse.
4. Relish technologies that allow you to separate storage and compute layers.
Group your use cases based on cost, performance, and scalability requirements. Separate your [high-performance + consistent-traffic] use-cases from [on-demand + inconsistent-traffic] use-cases. This gives you the flexibility to design the two solutions independently and keep your architecture simple and yet cost-effective and scalable. For [on-demand + low-traffic] use cases, you can easily exploit analytic platforms with the following features while for [high-performance + consistent-traffic] you can further optimize.
Separate your [high-performance + consistent-traffic] use-cases from [on-demand + inconsistent-traffic] use-cases. This gives you the flexibility to design the two solutions independently and keep your architecture simple and yet cost-effective and scalable. For on-demand + low-traffic use cases, you can easily exploit analytic platforms with the following features:
Separation of storage and computing
Historically, databases were seen as tightly coupled compute and storage components. But in the last few years “separation of storage & compute” has gained momentum. The ability to decouple compute and storage brings increased scalability and availability with dramatically reduced costs. This is possible because with this architecture, unlike typical databases, nodes don’t ‘own’ the data, so no need to rebalance the nodes rather all the nodes see the same data on the network and adding a node adds more computing power and much faster, since there is no movement of data. Which also means you can independently and elastically scale storage and compute. There are a couple of solutions that give you this, to name a few – Snowflake, Apache Drill, Athetha, Big Query, Redshift Spectrum.
Pay-as-you-use
With decoupled storage and compute, it is possible that you pay by query or by the amount of data scanned. Like, Big Query and Athena charge by per TB scanned or Snowflake which charges by computing power usage per-second. If the traffic is consistent during the day, this can highly optimise your cost.
5. Flip the 80/20 rule. Keep landing storage simple, so integrations are faster and easier to scale.
Once you have a pipeline setup and functioning smoothly, major time of your team should be spent on driving deeper insights or data integrations. And this is exactly where the data analytics team should be spending 80% of their time because this is what is going to bring revenue to your business.

If you are integrating several data sources, it is a good idea to keep your landing storage simple, fast to ramp-up for the integration team, and something that can easily integrate with other services. Let’s say — if you are in the AWS ecosystem and your team is already comfortable with S3, imagine using something like Cassandra as your landing storage. Though Cassandra is also now a managed service on AWS, the technology will still be a learning curve for the integration team. Also, S3 can much more easily integrate with your microservices — you can trigger Lambda functions when let’s say S3 objects arrive or trigger a workflow. Choosing a simple landing store that is handy for your team, and a fully going microservice can massively speed up integrations.
Go for serverless analytical platforms or hosted solutions as much as possible, especially if you are a start-up. It helps you lower the learning curve and reduce the operational risks. Other benefits being faster time to market, faster to scale, and reduced operational risk. Also, if your analytical system comprises many technologies, maintaining your own infrastructure for each can be resource-intensive for a startup.
To Summarise
It is important to design your data system in a way that you can rapidly develop and accommodate future business growth without putting too much cost upfront – design in tiers, keep things modular and do not put all the pressure on a single technology. Consider access patterns, performance and business criticality to pick right technology or to move data across storage tiers. Do orchestration and automation as you go. Do consider the expertise of the team and exploit the latest powerful analytic tools to reduce the prep time and risk to the business. Always have your best and optimal solution in mind and move towards it as you grow and gain more skills. Spend most of the time to drive value out of your data and rapid integrations which will directly impact the revenue of your business. Secure resources and time to innovate and innovate-on-time to stay ahead in the competition in today’s data driven world.

Written by Dan Turner
Product Manager and Business Developer at Streamhub