
Building an asynchronous solution for your analytic use-cases can be super powerful, especially building a deep-dive on-demand reporting solution. When we started building this at Streamhub, we found very little literature around this, so I am sharing this, hoping people pondering over this, can benefit from it. Our core analytical solution for such on-demand deep-dive use-cases is build upon Snowflake, based on design considerations listed in our previous blog, and our asynchronous layer runs over this.
What is an asynchronous service?
Asynchronous service is one of the common methods of interacting with backend systems for processes which takes a long time to compute. Our async approach is based on polling and involves the 3 simple steps:
- Execute the process asynchronously & get the processId immediately.
- Poll the status using the processId for every x seconds until the process completes
- Return the response
How to achieve this?
There are a number of ways to implement Async in Snowflake. Here is the method we found to be most effective. It is based on polling, and we made full use of Snowflake’s information_schema.query_history.
1. Executing an Async query
Scala and Python both have different ways of submitting an async query, Let’s look at both examples
Scala:
Once you get the connection string, using the preparedStatement you can unwrap the SnowflakePreparedStatement which allows you to execute an Async query using executeAsyncQuery() method. Return the queryId back to the service which triggered the sql.
def run(): (queryId, resultSet) = {
val sqlString = “Select * from dual”
val conn = getSnowflakeConnection()
val prep_statement = conn.prepareStatement(sqlString)
val (query_id, rs) =
// run Async query
if (asyncRequest) {
val resultSet = prep_statement.unwrap(classOf[SnowflakePreparedStatement]).executeAsyncQuery
val asyncQueryId = resultSet.unwrap(classOf[SnowflakeResultSet]).getQueryID
prep_statement.close()
conn.close()
(asyncQueryId, None)
}
// run sync query
else {
val resultSet = prep_statement.executeQuery
val queryId = resultSet.unwrap(classOf[SnowflakeResultSet]).getQueryID
(queryId, Some(resultSet))
}
} |
Code: Submitting Async & Sync queries to SF(Scala)
Python:
It is straightforward in python, just passing the param _no_results=True will submit an async query
def run(): sql_string = "select * from dual" cursor = get_snowflake_connection() if async_request: cursor.execute(sql_string, _no_results=True) query_id = cursor.sfqid return query_id, None else: cursor.execute(sql_string) result_set = cursor.fetchall() return query_id, result_set |
Code: Submitting Async & Sync queries to SF (Python)
2. Polling for results
Let’s poll the results, let’s say for every 5s using the queryId. Nice thing about Snowflake is that the history table provides the running status of the query in realtime and it is queryable as well as similar to any other table and it consumes a tiny amount of credits. This can be reduced by adding conditions in where clauses like warehouse, date etc to limit the search. I will leave that to you
So for every 5 s the below query will be used to check the status.
"""select query_id, execution_status, error_message from table(information_schema.query_history()) where query_id = '{0}'""".format(query_id) |
Sql: to poll history table
Snowflake History UI
Keep polling until the status is in running
def get_query_status(self, query_id): sql = """select query_id, execution_status, error_message from table (information_schema.query_history()) where query_id = '{0}'""".format(query_id) try: self.cursor.execute(sql) record = self.cursor.fetchone() if record is not None: print(record) if record[1] == 'FAILED_WITH_ERROR': return 500, record[1], record[2] else: return 200, record[1], record[2] else: return 404, "FAILED_WITH_ERROR", "query_id Not found" except snowflake.connector.errors.ProgrammingError as e: raise Exception('Error {0} ({1}): {2} ({3})'.format(e.errno, e.sqlstate, e.msg, e.sfqid)) |
Code: to get query status(Python)
3. Returning the response
Once the status is changed from running, we can handle it in different ways based on the status. Here we are interested mostly in Succeeded or Failed.
- If Succeeded(internally Snowflake returns execution status as SUCCESS), get the results from persisted cache using below query, and format the response according to your api response needs.
| “””select * from table (result_scan(‘{0}’))”””.format(query_id) |
Sql: to get result
- If Failed (internally Snowflake returns execution status as FAILED_WITH_ERROR) , the error_message from Snowflake can be directly redirected to the api response with an error code.
def get_results(self, query_id): sql = """select * from table (result_scan('{0}'))""".format(query_id) print(sql) items = [] try: self.cursor.execute(sql) result_set = self.cursor.fetchall() # get column headers columns = [col[0] for col in self.cursor.description] total_columns = len(columns) for row in result_set: row_list = (list(row)) items.append(dict(zip(columns, row_list))) results = {'columns': { 'total': total_columns, 'columns': columns }, 'items': items} return results except snowflake.connector.errors.ProgrammingError as e: raise Exception('Error {0} ({1}): {2} ({3})'.format(e.errno, e.sqlstate, e.msg, e.sfqid)) |
Code: to get formatted results
4. Asynchronous Flow
A simple flow depicting the async service built using Api-Gateway, Lambda, Snowflake
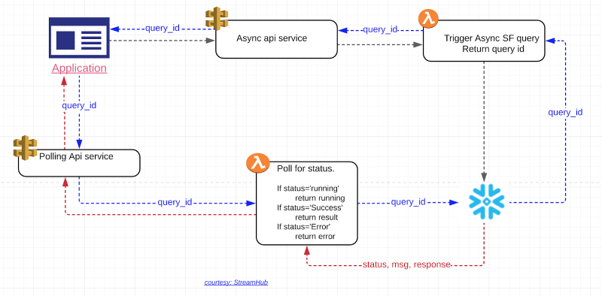
Asynchronous flow diagram
5. Time to weigh our apporach
Pros:
- If your processing function is using AWS Lambda then be aware of the Lambda timeout limit which is 15 mins.
- There is no need to build a logic to know the status of the query. Snowflake has a nice and reliable history table which maintains the status of the query in real time, which can be queried as well.
Cons:
- There is a small warehouse cost incurred each time a poll request is sent to the history table, whilst insignificant in small volumes this cost can quickly grow.
Hopefully you enjoyed this microblog, and it has helps you in building an asynchronous service on a modern data warehouse like Snowflake. Watch out for more of our technical blogs.

Sakthi Murugan
Senior Data Engineer
Sakthi is a highly experienced and accomplished programmer with a passion for all things Big Data, by night he is also a talented visual effects artist.